
Criminal actors are increasingly leveraging artificial intelligence technologies, particularly large language models (LLMs), to enhance their malicious operations and expand their attack capabilities. These sophisticated AI systems, originally designed to benefit society, are being weaponized through multiple vectors including unrestricted models, custom-built criminal platforms, and systematic circumvention of safety mechanisms.
The proliferation of AI-powered tools has democratized access to advanced computational capabilities, with platforms like Hugging Face now hosting over 1.8 million different models. While most commercial LLMs incorporate robust safety features including alignment training and protective guardrails, cybercriminals have developed sophisticated methods to bypass these restrictions or create entirely unfiltered alternatives for illicit purposes.
Unrestricted/Uncensored Language Models: The Pathway to Malicious AI
Technical Architecture and Accessibility
Uncensored LLMs operate without the ethical constraints and safety mechanisms that govern mainstream AI platforms. These unaligned models readily generate sensitive, controversial, or potentially harmful content in response to user prompts, making them particularly attractive to criminal actors.
These type of LLMs are quite easy to find. For example, using the cross-platform (Ollama) framework, a user can download and run an uncensored LLM on their local machine. Once it is running, users can submit prompts that would otherwise be rejected by more safety-conscious LLM implementations. The downside is that these models are running on users’ local machines and running larger models, which generally produce better results requires more system resources.
A more live example and usage of this kind of LLMs is the WhiteRabbitNeo that’s considered as “Uncensored AI model for (Dev) SecOps teams” which can support “use cases for offensive and defensive cybersecurity”. This LLM will happily write offensive security tools, phishing emails and more.
Research and Development of Unfiltered Systems
Academic researchers have published methodologies for systematically removing alignment constraints from existing open-source models.
These techniques involve modifying training datasets and fine-tuning base models to eliminate safety mechanisms, effectively creating bespoke uncensored systems. The technical feasibility of this approach has enabled widespread adoption among criminal communities, though it requires significant computational resources for optimal performance.

Criminal-Designed AI Platforms
Enterprising cybercriminals have developed dedicated AI platforms specifically designed for illegal activities, including applications such as GhostGPT, WormGPT, DarkGPT, DarkestGPT, and FraudGPT. These systems represent a commercialization of malicious AI capabilities, often marketed through dark web channels and criminal forums.
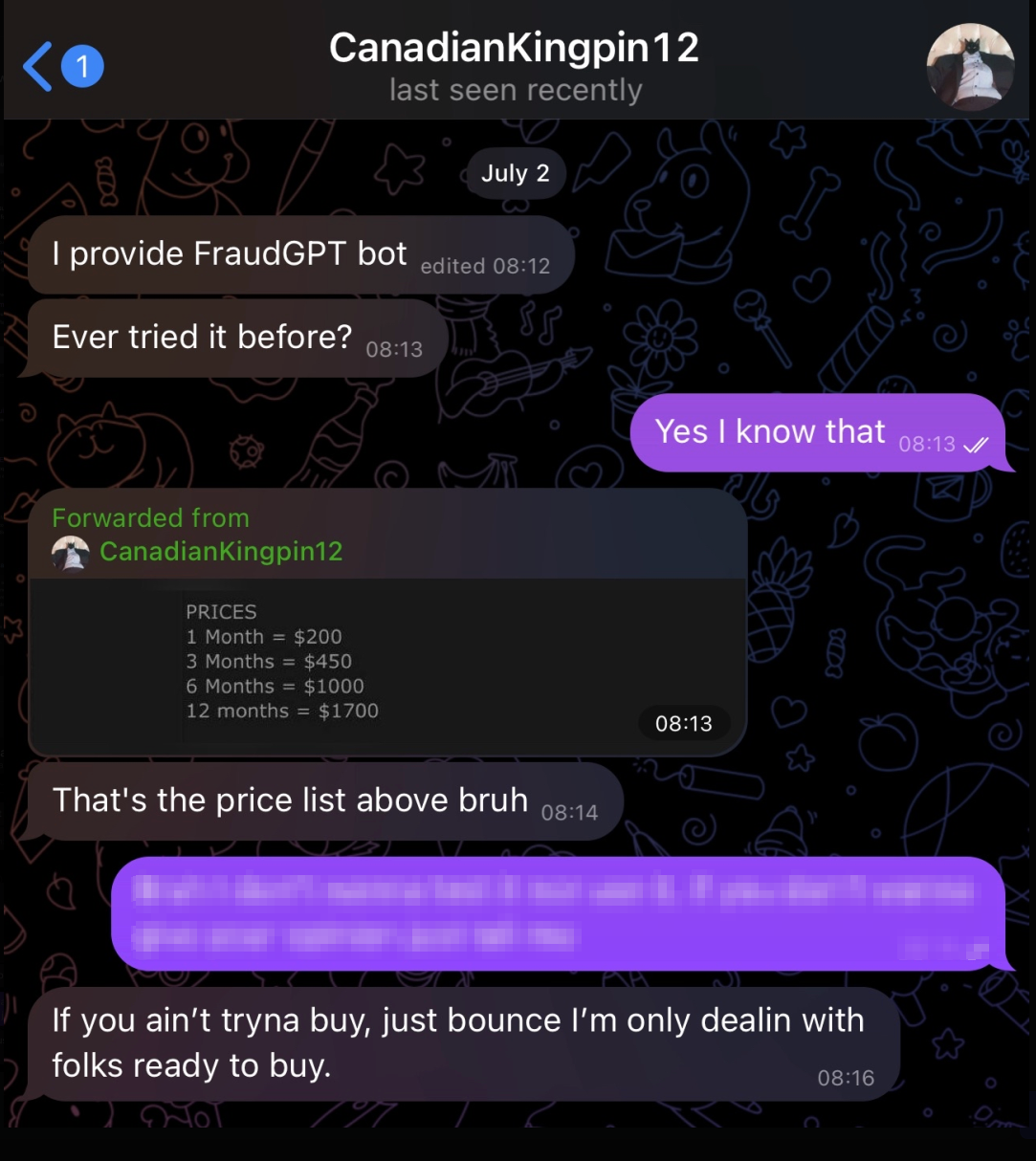
FraudGPT, developed by an actor known as CanadianKingpin12, exemplifies this trend with an extensive feature set advertised on dark web platforms and Telegram channels. The platform claims to offer capabilities including malicious code generation, undetectable malware creation, phishing page development, vulnerability scanning, and credit card verification services. Pricing models range from $200 monthly to $1,700 annually, indicating a structured commercial approach to criminal AI services.
Investigating into these criminal platforms reveals significant levels of fraud and scamming within the ecosystem itself. This pattern of scamming potential customers reflects broader trust issues within cybercriminal marketplaces and suggests that many advertised AI tools may be fraudulent schemes rather than functional platforms.
Advanced Jailbreaking Techniques
Given the limitations of uncensored LLMs and the prevalence of fraud among criminal AI platforms, many malicious actors have focused on exploiting legitimate LLMs through sophisticated jailbreaking techniques. These methods represent a form of prompt injection designed to circumvent alignment training and safety guardrails, effectively transforming compliant systems into tools for harmful content generation.

Meanwhile this also can be done as easy as using the uwu language sometimes…

Technical Approaches to AI Exploitation
Obfuscation and Encoding Attacks
Cybercriminals employ various text manipulation techniques to bypass content filters, including Base64 and ROT-13 encoding, alternative languages, leetspeak variations, Morse code, emoji substitution, and strategic insertion of Unicode characters. These methods exploit gaps in keyword-based filtering systems and can cause AI models to follow unintended execution paths.
Adversarial Suffix Techniques
This approach involves appending seemingly random text sequences to malicious prompts, which can trigger harmful responses through unpredictable model behavior patterns. The technique exploits the statistical nature of language model processing to achieve unintended outputs.
Role-Playing and Persona Attacks
Attackers prompt LLMs to adopt fictional personas or characters that ostensibly operate outside ethical constraints established by model creators. Popular variants include the “DAN” (Do Anything Now) technique and the “Grandma jailbreak,” which leverages social engineering principles to manipulate AI behavior.
Meta-Prompting Exploitation
This sophisticated approach leverages the model’s self-awareness of its limitations to devise workarounds, essentially enlisting the AI system in circumventing its own protective mechanisms.
Context Manipulation Strategies
These techniques include “Crescendo” attacks that progressively escalate prompt harmfulness to probe guardrail implementations, and “Context Compliance Attacks” that exploit conversational state management by injecting fabricated prior responses
Criminal Applications and Use Cases
Analysis of criminal LLM platforms reveals extensive programming capabilities designed to assist in malicious code development. These systems can generate ransomware, remote access trojans, system wipers, obfuscated code, shellcode, and automated exploitation scripts. The integration of AI into malware development represents a significant force multiplier for cybercriminal operations.
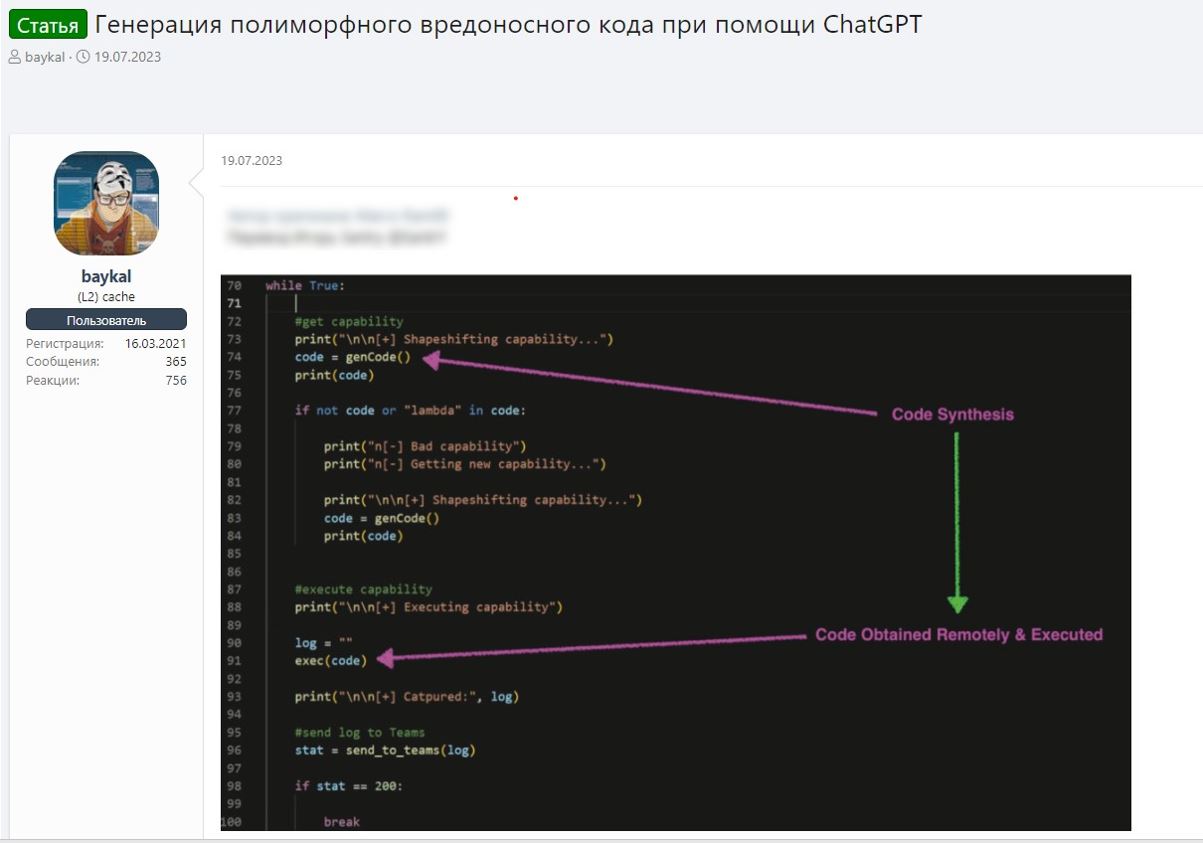
Research by Anthropic in December 2024 identified programming, content creation, and research as the top three legitimate uses for Claude LLM. Criminal platforms mirror these applications but redirect them toward illegal objectives, including malicious content generation, fraudulent material creation, and criminal intelligence gathering.
Targeting AI Systems: Attack Vectors Against LLMs
Model Backdooring and Supply Chain Attacks
LLMs themselves represent attractive targets for cybercriminals seeking to compromise AI systems and their users. The widespread use of Python’s pickle module for model serialization creates opportunities for code injection attacks. Malicious actors can embed executable code within model files that activates during the deserialization process, potentially compromising user systems upon model loading.
Research has identified over 100 malicious AI models on Hugging Face containing harmful payloads capable of establishing backdoor access to victim machines. Despite platform security measures including Picklescan and other detection tools, sophisticated attackers continue to successfully upload compromised models that evade automated scanning systems.
Retrieval Augmented Generation Vulnerabilities
LLMs utilizing Retrieval Augmented Generation (RAG) architectures face unique security challenges due to their reliance on external data sources. Attackers who gain access to RAG databases can poison lookup results by injecting malicious instructions or manipulating retrieved content. This poisoning can cause AI systems to generate harmful responses or leak sensitive information, even when queried by legitimate users.

Defensive Measures and Future Implications
The cybersecurity community has developed various defensive measures to combat AI abuse, including enhanced model scanning, improved content filtering, and behavioral analysis systems. However, the rapid evolution of attack techniques continues to outpace defensive capabilities, creating an ongoing arms race between security researchers and malicious actors.
Organizations implementing AI systems must consider comprehensive security frameworks that address both traditional cybersecurity concerns and AI-specific vulnerabilities. This includes careful vetting of AI models, implementation of robust access controls, and continuous monitoring of AI system behavior.
Conclusion
The exploitation of large language models by cybercriminals represents a significant evolution in threat actor capabilities and methodologies. While these technologies do not necessarily provide entirely novel attack vectors, they serve as powerful force multipliers that enhance the scale, sophistication, and effectiveness of traditional criminal operations. The convergence of accessible AI technology, criminal innovation, and inadequate defensive measures creates a complex threat landscape requiring coordinated response from technology developers, security researchers, and law enforcement agencies.
References

You might also like

What You Get After Running an SSH Honeypot for 30 days
After running an SSH honeypot on Ubuntu 24.04 for 30 days, it recorded 11,599 login attempts, revealing the persistent brute force activity and...

Hack the Hacker - How to Setup an SSH Honeypot
Discover how to set up an SSH honeypot to detect and analyze cyberattacks in real time. Learn to configure a fake SSH server that logs attacker...

The Magic of Tailscale
Access all your devices securely with Tailscale’s zero-config VPN. It offers end-to-end encryption, cross-platform support, and seamless remote...

PromptLock: The Dawn of AI-Powered Ransomware - A Deep Dive into ESET's Groundbreaking Discovery
ESET uncovers PromptLock, the first AI-powered ransomware using OpenAI’s gpt-oss:20b via Ollama API to generate dynamic Lua scripts for...
Discussion
Leave a Comment
Guest comments will be reviewed before appearing on the site.
cherif
January 12, 2026 at 06:20 PM